



La coerenza è l'ultimo rifugio delle persone prive d'immaginazione
MICROPROCESSORI E MICROCONTROLLORI
… studiare, studiare ed ancora studiare,
è il solo modo di capire quanto possa
essere grande sia la propria ignoranza!
IL MICROCONTROLLORE ARM





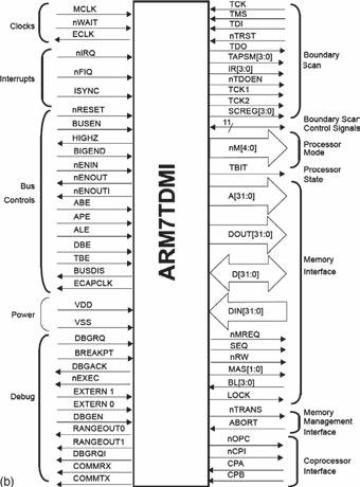
Il microcontrollore ARM
L’ARM (Advanced RISC Machine) (schema a
blocchi in figura (a) e piedinatura in figura (b) fa parte di una famiglia
di micro embedded che:
•
è di fascia medio/alta a 32 bit;
•
occupa il 75% del mercato;è a basso consumo;
•
domina il settore dei componenti portabili per i quali è importante
il risparmio energetico;
•
può supportare anche sistemi operativi, quale ad esempio Linux
se è dotato dell’unità MMU;
•
è uno dei processori con un più elevato numero di licenze
di sviluppo.
L’unità MMU (Memory Management Unit) è un
componente hardware che gestisce le richieste
di accesso della CPU alla memoria.
Infatti la memoria è vista dalla CPU con dime-
-nsioni virtuali, ovvero più grandi di quelle
effettive poiché la memoria a semiconduttore
è integrata con la memoria di massa.
Pertanto la MMU traduce gli indirizzi virtuali
generati dalla CPU in indirizzi fisici.
L’ARM è un processore a 32 bit che può
elaborare dati di lunghezza minore: a 8 bit
(1 byte) e a 16 bit (halfword)
come nella sottostante tabella.
Tipologia di dati dell’ARM


Byte
Byte
Byte
Byte
4x8 bit
Halfword
Halfword
2 × 16 bit allineati su 2 byte
Word
1 × 32 bit allineati su 4 byte
Quando però questi dati sono localizzati nei
registri devono essere ordinati e allineati
secondo due possibili convenzioni:
• little endian;
• big endian.
Un dato localizzato in memoria è ordinato per
default secondo la convenzione little endian.
Nella convenzione classica little endian, il bit
meno significativo è a destra, quello più
significativo è a sinistra.
Nella convenzione big endian invece la
posizione è invertita.
Tutte le istruzioni che prelevano un dato di
tipo byte o halfword dalla memoria e lo devono
caricare in un registro, estendono a 32 bit il dato in un modo tale da completare la word
con segno o senza segno.
Se l’istruzione indica un caricamento senza segno, il dato viene memorizzato nei bit meno
significativi del registro azzerando tutti i restanti bit più significativi.
Se l’istruzione indica invece un caricamento del dato con segno, i restanti bit devono avere
un valore corrispondente al segno.
Caratteristiche degli ARM:
• processore RISC a 32 bit, istruzioni a 32 bit;
• 37 integer register a 32 bit;
• pipeline a 3 livelli nella versione ARM7;
• pipeline a 5 livelli nella versione ARM9;
• cache size in funzione dell’implementazione;
• struttura von Neumann in ARM7;
• struttura Harvard in ARM9;
• formato del dato a 8/16/32 bit;
• 7 modi di operare.
Il modello RISC conferisce al micro le clas-
-siche caratteristiche di questo tipo di archi-
-tettura:
•
una grande quantità di registri (32) tutti
uniformi a 32 bit, ognuno utilizzabile per
un qualsiasi scopo e hard-wired, ovvero in
modo indipendente dagli altri;
•
un modello load/store di processo dei dati
ovvero le istruzioni possono operare sui dati
solo con i registri interni al core del micro-
-controllore e non direttamente in memoria;
ciò richiede che tutti i dati siano caricati nei
registri prima che l’operazione venga eseguita;
successivamente il risultato può essere usato
per ulteriori processi o localizzati in memoria;
•
un piccolo numero di modi di indirizzamento tutti con filosofia load/store;
•
ogni istruzione di lunghezza fissa e uniforme (32 bit).
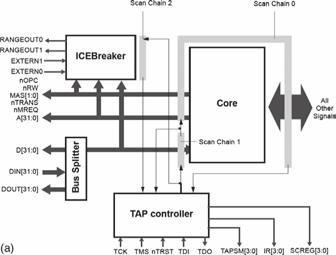
Nello soprastante schema a blocchi (a) si pone in evidenza che il micro si compone di un
core e di una serie di registri.
In aggiunta a queste caratteristiche tradizionali del RISC, il sistema ARM è dotato anche di:
•
ALU e barrel shifter separati (vedi soprastante schema a blocchi) che consentono un
controllo supplementare dell’elaborazione dei dati per elevare la velocità di esecuzione;
il barrel shifter è un registro che consente, con un solo colpo di clock, di shiftare e
ruotare il dato per svolgere operazioni aritmetiche;
•
modi di autoincremento e autodecremento degli indirizzi per migliorare l’operazione dei
cicli di programma;
•
esecuzione condizionale di istruzioni per evitare lo svuotamento della pipeline in caso di
stallo e quindi incrementare la velocità di esecuzione.
I dati e le istruzioni vengono caricati dalla memoria nei registri. Tutte le operazioni
sui dati si eseguono nei registri e non in memoria. Nell’ARM7 sono stati implementati
3 livelli di pipeline, mentre nell’ARM9 sono
implementati 5 livelli (come nella figura a lato)

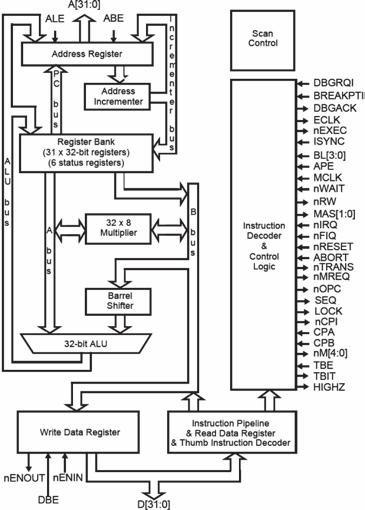
Schema a blocchi del core del microcontrollore
ARM7TDMI (ARM Powered).
Livelli di pipeline negli ARM
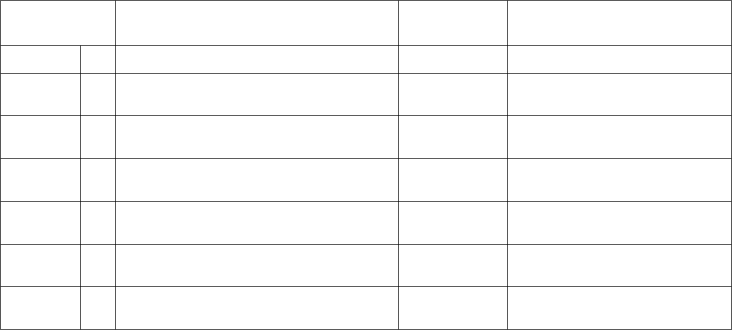
Modalità di funzionamento
Dalla versione 4 in poi il micro supporta 7
modalità di funzionamento (descritta nella
sottostante tabella).
La maggior parte dei programmi utenti è
eseguita in modo User.
In questa modalità il programma in esecuzione
non può accedere ad alcuna risorsa protetta
del sistema, né cambiare modalità di funziona-
-mento.
Ciò è possibile solo inducendo una eccezione.
Con le altre 6 modalità di funzionamento, definite
privileged modes, è possibile il pieno accesso
alle risorse protette del sistema.
È consentito passare liberamente da un modo privilegiato ad un ad un altro.
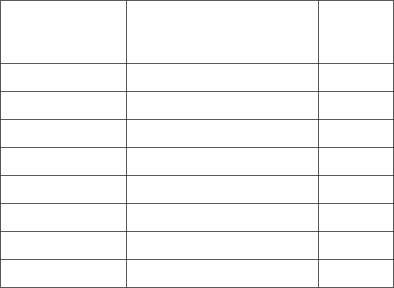
Modalità di esecuzione.



Processor
mode
Description
Code M(4-0)
Accessible register
User
usr
Normal program execution mode
0b10000
PC, R14 to R0,CPSR
FIQ
fiq
Fast Interrupt for high-speed data transfer
0b10001
PC, R14_fiq to R8_fiq,R7 to R0,
CPSR, SPSR_irq
IRQ
irq
Used for general-purpose interrupt
handling
0b10010
PC, R14_irq, R13_irq. R12 to R0,
CPSR, SPSR_irq
Supervisor
svc
A protected mode for the operating
system
0b10011
PC, R14_svc, R13_svc, R12 to
R0, CPSR, SPSR_svc
Abort
abt
Implements virtual memory and/or
memory protection
0b10111
PC, R14_abt, R13_abt, R12 to
R0,CPSR, SPSR_abt
Undefined
und
Support software emulation of hardware
coprocessors
0b11011
PC, R14_und, R13_ind, R12 to
R0,CPSR, SPSR_und
System
sys
Runs privileged operating system tasks
0b11111
PC, R14 to R0, CPSR (ARM
architecture v4 and above)
Le modalità FIQ, IRQ, Supervisor, Abort e Undefined sono chiamate exceptions modes.
Tali modalità sono richiamate con eccezioni specifiche per risolvere qualunque situazione
compresi gli interrupt.
In pratica ogni exception è un sottoprogramma che viene richiamato in determinate
condizioni che si verificano nello stato del sistema.
Ognuna di queste modalità ha a disposizione i registri comuni a tutte le modalità e un
numero supplementare di tali registri che servono a evitare l’alterazione del modo User
quando subentra un’eccezione.
Questo metodo di operare ha come finalità lo svolgimento dei sottoprogrammi in un tempo
minore.
Nella tabella sono evidenziati con sfondo grigio i registri visibili solo allo stato relativo.
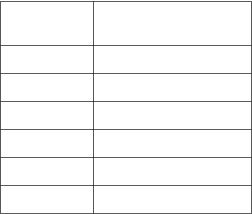
Set di registri attivi nelle varie modalità.

User
Modes
System
Previleged modes
Exception modes
Supervisor
Abort
Undefined
Interrupt
Fast Interrupt
R0
R0
R0
R0
R0
R0
R0
R1
R1
R1
R1
R1
R1
R1
R2
R2
R2
R2
R2
R2
R2
R3
R3
R3
R3
R3
R3
R3
R4
R4
R4
R4
R4
R4
R4
R5
R5
R5
R5
R5
R5
R5
R6
R6
R6
R6
R6
R6
R6
R7
R7
R7
R7
R7
R7
R7
R8
R8
R8
R8
R8
R8
R8_fiq
R9
R9
R9
R9
R9
R9
R9_fiq
R10
R10
R10
R10
R10
R10
R10_fiq
R11
R11
R11
R11
R11
R11
R11_fiq
R12
R12
R12
R12
R12
R12
R12_fiq
R13
R13
R13_svc
R13_abt
R13_und
R13_irq
R13_fiq
R14
R14
R14_svc
R14_abt
R14_und
R14_irq
R14_fiq
PC
PC
PC
PC
PC
PC
PC
CPSR
CPSR
CPSR
CPSR
CPSR
CPSR
CPSR
SPSR svc
SPSR abt
SPSR und
SPSR irq
SPSR fiq
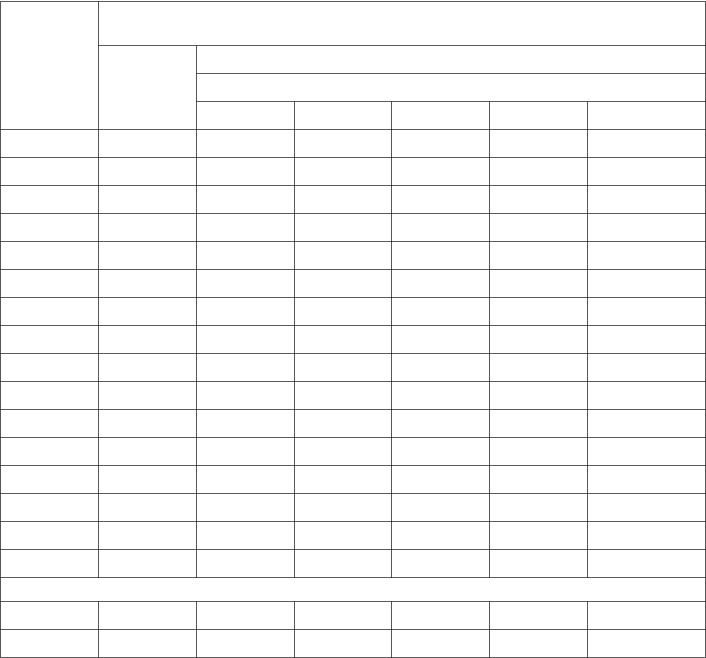
Il modo System non si inserisce con alcuna eccezione ed ha esattamente gli stessi registri
disponibili del modo User, ma, essendo un modo privilegiato, non è soggetto alle limitazioni
del modo User.
Si tratta di una modalità a disposizione del sistema operativo per l’accesso alle risorse del
sistema evitando però l’uso dei registri addizionali associati ai modi eccezione.
Tale modo di esecuzione assicura che la task non è alterata da nessuna eccezione che
interviene.
Registri
L’ARM ha un totale di 37 registri, di cui 30 sono di uso generale, 6 di stato e un program
counter.
Nella soprastante tabella è illustrata la mappa dei registri dell’ARM.
Solo 15 dei registri di uso generale sono disponibili in qualsiasi momento secondo i modi
del processore.
I registri da R0 a R7 sono di uso assolutamente generale e sempre disponibili.
Possono essere usati per trasferimento dei dati da e verso la memoria e per eseguire
operazioni sugli operandi.
I registri da R8 a R12 sono comuni a tutti i modi di funzionamento del micro
con l’eccezione del modo FIQ. Questi registri di uso generale non hanno alcun
compito specifico ma, se il processore
è nel modo interrupt veloce, vengono sostituiti con i relativi registri FIQ. Anche se
questi registri non hanno un compito specifico, possono tuttavia memorizzare
informazioni tra fast interrupt.
In tal modo si può rendere ancora più veloce l’esecuzione del sottoprogramma relativo
all’interrupt.
I registri di uso generale possono essere usati per manipolare dati a 8, 16 e a 32 bit.
Se il registro a 32 bit viene utilizzato per memorizzare dati da 8 bit, si occupano i bit
meno significativi.
R13-R15 sono registri speciali e hanno un compito specifico:
•
R13 funge da Stack Pointer;
•
R14 è il Link Register per memorizzare l’indirizzo di ritorno in una chiamata di
subroutine;
•
R15 è il Program Counter.
Ogni modo di funzionamento possiede una propria coppia di registri R13 e R14 per avere
uno stack privato e una via più efficiente per il ritorno da eccezione.
Il modo FIQ possiede una copia fisica dei registri da R8 a R12 per servire una chiamata a
un interrupt veloce senza la necessità di salvare il contenuto in registri alternativi.
L’User e il System usano lo stesso banco di registri generali.
Il CPSR (Current Program Status Register) (vedi sottostante figura) è il registro che:
• contiene i flags di stato;
• gestisce le eccezioni.
indicates that the normal register used by User or System mode has been replaced
by an alternative register specific to the exception mode
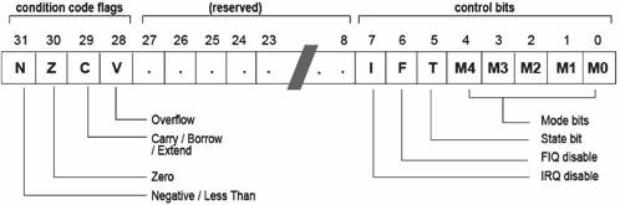
I suoi bit hanno il seguente significato:
• N, bit che indica un risultato negativo di un’operazione.
• Z, bit di zero indica un risultato nullo;
• C, bit di carry nell’aritmetica senza segno e shift;
• V, bit che indica l’overflow nell’aritmetica con segno in complemento a 2;
• I, bit che indica lo stato degli interrupt generici;
• F, bit che indica lo stato degli interrupt veloci (FIQ);
• T, stato di Thumb;
• M0-M4, definiscono il modo di esecuzione del processore.
Il registro SPSR (Saved Program Status Register) serve a salvare i dati di CPSR durante
l’esecuzione di una eccezione.
Dalla precedente tabella, si nota che per ogni modo esiste un SPSR tranne che per i modi
User e System per i quali non è prevista la gestione di un’eccezione.
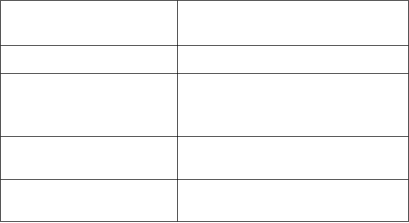
Condizioni delle istruzioni
In ogni istruzione 4 bit sono dedicati alla codifica delle condizioni necessarie perché
l’istruzione debba essere eseguita.
Nella sottostante tabella sono riassunti i codici e le mnemoniche delle condizioni.
I bit di condizione per default, memorizzati nel registro di stato, sono alterati dalle
istruzioni solo se il bit S (Set Condition Codes) è settato a 1.
Per settare a 1 il bit S si adottano le istruzioni con la «S» finale: ADDS, SUBEQS, RSCS, …
Per le istruzioni CMP, CMN, TEQ, e TST il bit S è sempre 1.
Condizioni per l’esecuzione delle istruzioni


Mnemonica
Significato
Flag di condizione
Opcode(31-28)
EQ
Uguali
Z=1
0000
EQ
Non uguali
Z=0
0001
CH/HS
Carry attivato/senza segno maggiore o uguale
C=1
0010
CC/LO
Carry disattivato/senza segno minoreguali
C=0
0011
MI
Negativo
N=1
0100
PL
Positivo o zero
N=0
0101
VS
Overflow
V=1
0110
VC
Non overflow
V=0
0111
HI
Senza segno maggiore
C=1 e Z=0
1000
LS
Senza segno minore o uguale
C=0 e Z=1
1001
GE
Con segno maggiore o uguale
N=V
1010
LT
Con segno minore
N!=V
1011
GT
Con segno maggiore
Z=0 e N=V
1100
LE
Con segno minore o uguale
Z=1 o N!=V
1101
AL
Sempre (per default)
-
1110
NV
Mai
-
1111

Istruzioni LDM/STM per stack


Istruzione
Modi di indirizzamento
Tipo di stack
LDM (load)
IA (Increment After)
FD (Full Descending)
STM (store)
IA (Increment After)
EA (Empty Ascending)
LDM (load)
IB (Increment Before)
ED (Empty Descending)
STM (store)
IB (Increment Before)
FA (Full Ascending)
LDM (load)
DA (Decrement After)
FA (Full Ascending)
STM (store)
DA (Increment After)
ED (Empty Descending)
LDM (load)
DB (Decrement Before)
EA (Empty Ascending)
STM (store)
DB (Decrement Before)
FD (Full Descending)

La memoria stack
Lo stack è una memoria di tipo LIFO (Last In First Out) utilizzata dal micro per salvare gli
indirizzi delle istruzioni contenute nei registri prima dell’esecuzione di una subroutine o di
una routine di servizio di un interrupt allo scopo di garantire il rientro nel programma
principale.
Nel processore ARM il contenuto del registro LR deve essere salvato nell’area stack prima
che dall’interno di una subroutine ne venga richiamata un’altra, allo scopo di ripristinare in
modo corretto la successione degli indirizzi di ritorno alle subroutine chiamanti.
Il registro R13 (SP, Stack Pointer) ha lo scopo di identificare l’indirizzo della testa dello
stack.
Gli stack sono gestiti con le istruzioni LDM (Load Multiple Register) e STM (Store Multiple
Register).
Nella tabella qui sotto sono riportati i 4 tipi di stack supportati.
Lo stack è full se SP punta all’ultimo dato
inserito.
Lo stack è empty se SP punta al 1a locazione
libera.
Lo stack può essere discendente in funzione
di SP se deve essere incrementato o
decrementato in seguito all’inserimento.
Nella figura (a) a lato sono illustrate le varie
tipologie di stack e in figura (b) è riportata
la mnemonica dei vari modi di indirizzamento.

Eccezioni
L’ARM è provvisto di 7 tipi di eccezioni,
mostrate nella tabella a lato e un ottavo
tipo particolare (Address Exception) con un
address space a 24 bit.
•
Reset: inizializza il micro ma non vi è un
ritorno.
•
Undefined Instruction: eccezione interna
al micro quando si preleva una codifica
non valida di una istruzione.
•
Software Interrupt: eccezione generata
dall’istruzione SWI; la routine di
servizio attiva una chiamata a sistema,
viene eseguita in modo privilegiato.
•
Prefetch Abort: eccezione generata dal
segnale d’ingresso ABORT emesso dalla
MMU nel tentativo di accedere ad un
indirizzo non valido di memoria.
Può essere utilizzato per implementare
una memoria virtuale.
•
Data Abort: in questo caso il segnale
ABORT è generato nella fase di
esecuzione di una istruzione.
•
IRQ (Interrupt ReQuest): eccezione
generata attivando il segnale
d’ingresso IRQ
•
FIQ (Fast Interrupt reQuest): eccezione
generata dal segnale d’ingresso FIQ.
Tipologie di eccezioni.


Hard Vector
or Address
(Hex)
Exception
Mode
0x00000000
Reset
SVC
0x00000004
Undefined Instruction
UNDEF
0x00000008
Software Instruction (SWI)
SVC
0x0000000c
Prefetch Abort
ABORT
0x00000010
Data Abort
ABORT
0x00000014
Address Exception
SVC
0x00000018
IRQ Interrupt
IRQ
0x0000001c
FIQ Interrupt
FIQ
Priorità delle eccezioni.


Priority
Exception
Highest 1
Reset
2
Data Abort
3
FIQ
4
IRQ
5
Prefetch Abort
Lowest 6
Undefined Instruction
Tipologie di stack (a) e tabella mnemonica dei vari modi
di indirizzamento dello stack (b) (ARM Powered)
Le eccezioni hanno le priorità indicate nella
tabella mostrata a lato.
Ad ogni eccezione corrisponde un hard vector che consiste
in un indirizzo del codice programma dove è residente il
sottoprogramma relativo a quella eccezione.
L’elaborazione di una eccezione coinvolge i registri
R14 (LR), R15 (PC) e SPSR e si svolge secondo i seguenti
passi:
•
il contenuto del PC (R15) viene salvato in LR (R14)
corrispondente all’eccezione in corso di elaborazione.
•
Nel PC viene inserito l’hard vector dell’eccezione.
•
il contenuto di CPSR viene salvato nel SPSR corrispo-
-ndente all’eccezione in corso di elaborazione;
•
vengono disabilitate le interruzioni comuni;
•
se l’eccezione è Reset o FIQ vengono
disabilitate le interruzioni veloci.
L’indirizzo di ritorno, salvato nel registro
R14 exception mode, dipende dal tipo di
eccezione secondo la tabella a lato.
Indirizzo di ritorno secondo i tipi di eccezione.


Eccezione
Indirizzo
Reset
Non prevedibile
Undefined Instruction
Software Instruction
Prefetch Abort
Indirizzo istruzione
dell’eccezione + 4
Data Abort
Indirizzo istruzione
dell’eccezione + 8
IRQ e FIQ
Indirizzo istruzione successive al
codice interrotto
Il ritorno al codice precedentemente
interrotto dalla modalità inserita avviene
dopo aver servito la subroutine di servi-
-zio dell’eccezione.
Ciò avviene con il ripristino di PC e CPSR.
Le istruzioni che consentono il ripristino
sono:
•
l’istruzione multipla LDM specificando
nella lista dei registri destinazione anche R15;
•
le istruzioni di manipolazione dati con destinazione PC e bit S impostato.
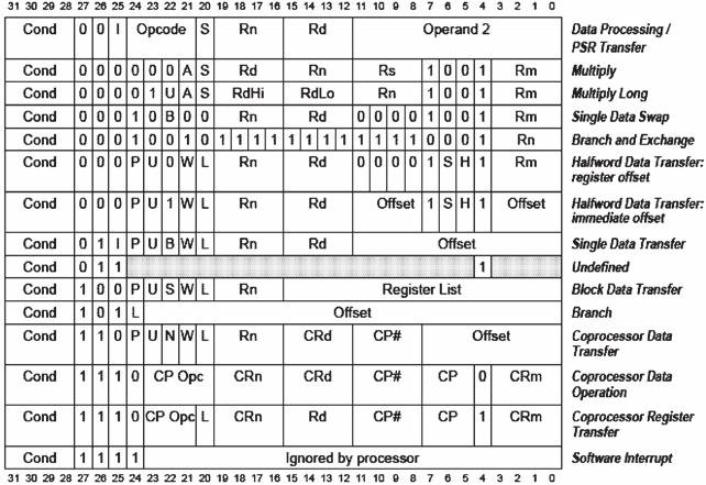
Set di istruzioni
La tabella che segue, riporta la lista della mnemonica delle istruzioni che possono essere
classificate in 6 tipologie:
1.
spostamento dati (data-processing instructions);
2.
aritmetiche;
3.
manipolazione logica e di bit (status register transfer instructions);
4.
accesso in memoria (load and store instructions);
5.
controllo del flusso (branch instructions);
6.
controllo del sistema/privilegiate (coprocessor and exception-generating instructions)
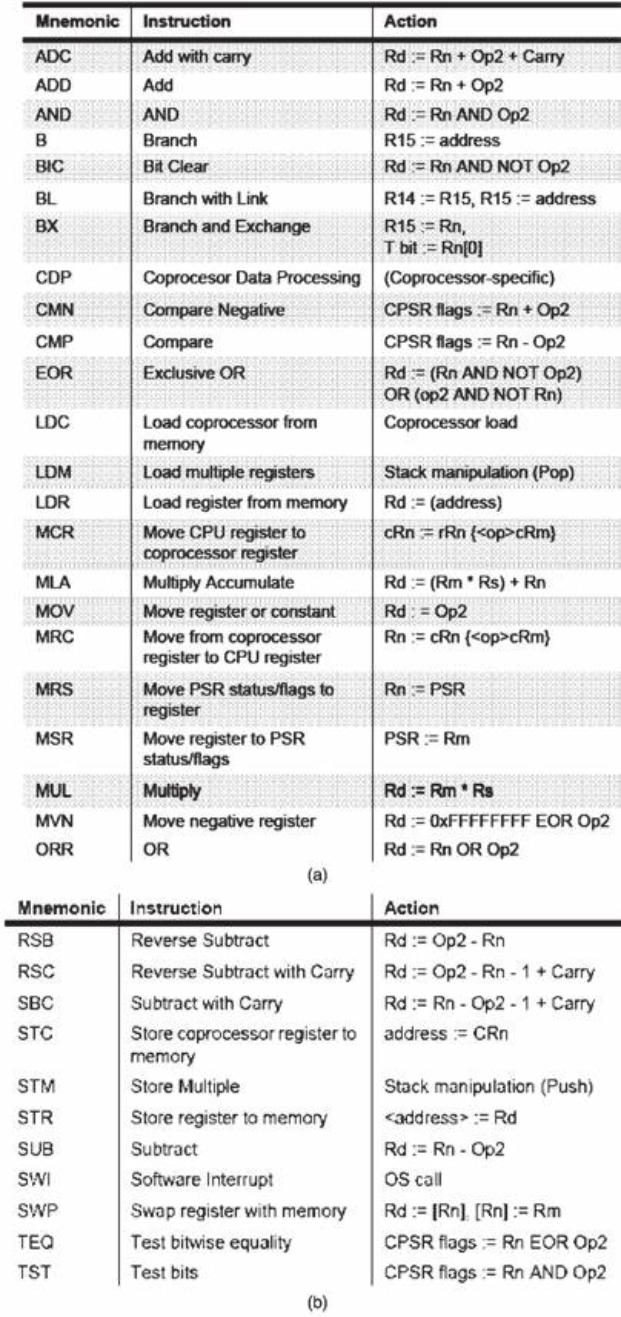
Mnemonica delle istruzioni


Operation
Mnemonic
Meaning
Operation
Mnemonic
Meaning
ADC
Add with Carry
MVN
Logical NOT
ADD
Add
ORR
Logical OR
AND
Logical AND
RSB
Reverse Substract
BAL
Unconditional Branch
RSC
Reverse Subtract with Carry
B(cc)
Branch on Condition
SBC
Subtract with Carry
BIC
Bit Clear
SMLAL
Mult Accum Signed Long
BLAL
Unconditional Branch and
Link
SMULL
Multiply Signed Long
BL(cc)
Conditional Branch and Link
STM
Store Multiple
CMP
Compare
STR
Store Register (Word)
EOR
Exclusive OR
STRB
Store Register (Byte)
LDM
Load Multiple
SUB
Subtract
LDR
Load Register (Word)
SWI
Software Interrupt
LDRB
Load Register (Byte)
SWP
Swap Word Value
MLA
Multiply Accumulate
SWPB
Swap Byte Value
MOV
Move
TEQ
Test Equivalence
MRS
Load SPSR or CPSR
TST
Test
MSR
Store to SPSR or CPSR
UMLAL
Mult Accum Unsigned Long
MUL
Multiply
UMULL
Multiply Unsigned Long
Istruzioni di salto (branch instructions)
Vi sono due istruzioni di salto relativo: B (Branch) e BL (Branch and Link).
Una istruzione di salto si svolge normalmente in tre step:
•
nel PC (R15) viene caricato un valore pari alla somma del valore corrente e di un offset
relativo specificato nel codice dell’istruzione;
•
se il salto è a una subroutine, l’indirizzo di ritorno è memorizzato nel Link Register;
l’istruzione di salto condizionato/incondizionato è costituito dai bit indicati nella
sottostante tabella.
I 4 bit più a sinistra, presenti in alcune istruzioni, definiscono la condizione booleana
che deve essere soddisfatta affinché l’istruzione venga eseguita, i successivi 3 bit il
tipo di condizione, i 24 bit meno significativi costituiscono l’offset da aggiungere al
valore corrente del PC.
• Il bit 24, che è L, pone il PC in R14 per il ritorno.
Le istruzioni di salto sono anche tutte quelle istruzioni che hanno come destinazione il PC e
il cui indirizzo di salto è indicato in un registro.
Se il salto è condizionato il bit L indica che il PC deve essere salvato in R14 per avere la
garanzia del ritorno da un sottoprogramma.
Nella tabella che segue è riportato il codice dell’istruzione.
Nel codice del salto incondizionato (tabella sottostante) alla modalità Thumb l’indirizzo è
costituito dai 24 bit di offset da sommare/sottrarre al PC.
Codice dell’istruzione di salto a modalità Thumb

31 28
27 25
24
23 0
cond
101
H
24-bit signed word offset

Codice dell’istruzione di salto condizionato

31 28
27 6
5
4
23 0
cond
0001001011111111111100
L
1
24-bit signed word offset

Codice dell’istruzione di salto condizionato

31 28
27 25
24
23 0
1111
101
H
24-bit signed word offset

Esempio
Un salto incondizionato.
…
B
LABEL
;unconditional jump…
LABEL …
; …to here
To execute a loop ten times:
MOV r0, #10
;initialize loop counter
LOOP …
SUBS r0, #1
;decrement counter setting CCs
BNE LOOP
;if counter<>0 repeat loop…
…
; …else drop through
To call a subroutine:
…
BL SUB
;branch and link to subroutine SUB
…
;return to here
…
SUB …
;subroutine entry point
MOV PC, r14 ;return
Esempio
B{L}X{<cond>} Rm
BLX <target address>
<target address> è di solito una label nel codice assembler;
l’assembler genererà l’offset (che sarà la differenza fra l’indirizzo di parola del target
e l’indirizzo dell’istruzione di salto più 8) e setta il bit H se necessario.
Un salto incondizionato:
BX r0
;branch to address in r0
;enter Thumb state if r0 [0]=1
Una chiamata a una subroutine Thumb:
CODE32
;ARM code follows
…
BLXT SUB ;call Thumb subroutine
Istruzioni data-processing
Le istruzioni data-processing consentono i calcoli nei registri di uso generale.
Possono essere di quattro tipi:
• aritmetico/logiche;
• di confronto;
• multiple;
• di zero principali di conteggio.
Vi sono 12 istruzioni aritmetico/logiche che condividono un formato comune.
Tali istruzioni consentono di eseguire operazioni aritmetiche e logiche su due operandi e
scrivono il risultato in un registro destinazione.
Questo tipo di istruzioni possono avere delle opzioni per aggiornare i bit di condizione in
base al risultato.
Se l’istruzione manipola due operandi, dei due:
•
uno è sempre in un registro;
•
l’altro può essere assegnato in due modi:
– un valore immediato;
– un valore di registro eventualmente shiftato.
Se l’operando è un registro shiftato, l’ammontare dello shift può essere un valore imme-
-diato o il valore di un altro registro.
Ogni istruzione aritmetico/logica può eseguire sia operazioni aritmetico/logiche sia
operazioni di shift.
Ne consegue che questo micro non ha istruzioni dedicate per lo shift.
Poiché il PC (R15) è un registro di uso generale, può essere usato anche come destinazione
del risultato delle istruzioni aritmetico/logiche, allo scopo di implementare più facilmente
una grande varietà di istruzioni di salto.
L’ARM è dotato di quattro istruzioni di confronto che usano lo stesso formato delle istruzioni
aritmetico/logiche.
Queste istruzioni eseguono operazioni aritmetiche e logiche su due operandi ma
non scrivono il risultato in un registro, aggiornano invece sempre i bit di condizione.
Gli operandi hanno la stessa forma delle istruzioni aritmetico/logiche, compreso la capacità
di comprendere un’operazione di shift.
Le istruzioni multiple possono essere suddivise in due tipi di categorie:
• risultato a 32 bit memorizzato in un registro;
• risultato a 64 bit memorizzato in due registri separati.
Le istruzioni Count Leading Zeros (CLZ) calcolano il numero di bit 0 da inserire nella
posizione più significativa del registro per completare il valore del registro.
Il numero di bit 0 viene scritto nel registro destinazione dell’istruzione CLZ.
ADC (Add with Carry)
ADC{<cond>}{S} Rd, Rn, <shifter_operand>
•
Con S = 1 si modificano i bit di flag N, Z, C, V.
•
Significato: somma il contenuto del registro Rn, dello <shifter_operand> e del carry e
mette il risultato in Rd.
•
L’istruzione viene utilizzata per somme di precisione a più di 32 bit.
Esempio
Somma di due dati a 64 bit: l’istruzione esegue la somma del primo operando che si trova
in R0 e R1 con il secondo operando che si trova in R2 e R3.
Il risultato viene scritto in R4 e R5.
ADDS R4, R0, R2
;somma i bit meno significativi
ADC R5, R1, R3
;somma i bit più significativi
ADD (Add)
ADD {<cond>}{S} Rd, Rn, <shifter_operand>
•
Con S = 1 si modificano i bit di flag N, Z, C, V.
•
L’istruzione svolge un’operazione di somma tra il dato presente in Rn e lo
<shifter_operand> ponendo il risultato in Rd.
AND (Bitwise logical AND)
AND {<cond>}{S} Rd, Rn, <shifter_operand>
•
Con S = 1 si modificano i bit di flag N, Z, C.
•
L’istruzione esegue un’operazione AND tra il contenuto di Rn e lo <shifter_operand>, il
risultato è memorizzato in Rd.
Esempio
AND R0, R1, #0xff000000
;i primi 8 bit di R1 vengono
;memorizzati in R0
BIC (Bit Clear)
BIC {<cond>}{S} Rd, Rn, <shifter_operand>
•
Con S = 1 si modificano i bit di flag N, Z, C.
•
L’istruzione esegue una AND bit a bit tra il contenuto di Rn e il complemento a 1 dello
<shifter_operand>, il risultato è memorizzato in Rd.
Se lo <shifter_operand> funge da maschera, l’istruzione consente l’azzeramento bit
per bit del contenuto di Rn.
Esempio
BIC R0, R0, #0xff000000
;azzeramento dei primi 8 bit di R0
CMN (Compare Negative)
CMN {<cond>}{S} Rd, Rn, <shifter_operand>
•
Vengono modificati i flag N, Z, C, V.
•
L’istruzione esegue la somma di Rn + <shifter_operand> come Rn −
-(−<shifter_operand>), pertanto confronta Rn e il complemento a 2 di <shifter_
_operand>.
I bit di condizione sono settati in base al risultato.
Esempio
CMN R0, R1, LSL #1
CMP (Compare)
CMP {<cond>} Rd, <shifter_operand>
•
Vengono modificati i flag N, Z, C, V.
•
L’istruzione eseguendo la differenza Rn − <shifter_operand>, confronta Rn e il
contenuto di <shifter_operand>; i bit di condizione sono settati in base al risultato.
Esempio
CMP R0, R1, ASR #2
EOR (Exclusive OR)
EOR {<cond>}{S} Rd, Rn, <shifter_operand>
•
Vengono modificati i flag N, Z, C, V.
•
L’istruzione esegue l’OR esclusivo tra il contenuto di Rn e lo <shifter_operand> e
pone il risultato in Rd.
Se lo <shifter_operand> è considerato come una maschera, l’istruzione consente
di ottenere il complemento a 1 del contenuto di Rn.
Esempio
EOR R0, R1, #6
MLA (Multiply Accumulate)
MLA {<cond>}{S} Rd, Rm, Rs, Rn
•
Con S = 1 si modificano i bit N, Z, C (non prevedibile).
•
L’istruzione esegue la seguente operazione Rm ∙ Rs + Rn e pone il risultato in Rd.
Esempio
MLA R3, R1, R2, R3 ;R3 <-;R1*R2+R3
MOV (Move)
MOV {<cond>}{S} Rd, <shifter_operand>
•
Con S = 1 si modificano i bit N, Z, C.
•
L’istruzione pone in Rd il contenuto di <shifter_operand>.
Se i bit di condizioni vengono modificati, i nuovi valori dipendono dal contenuto
di Rd e dal carry dello shifter.
Esempio
MOV R3, #0
;R3 <- 0
MOVVSS R2, #0xf0000000
;se V=1 allora R2 <- 0xf0000000,
;N ← 1,
;Z <. 0, C <- 0
MOV R0, R1, ROR #3
;R0 <- R1 ruotato a destra di 3 posizioni
MOVS PC, LR
;PC <- LR, CPSR=SPSR_<modo> ritorno da RSI
MUL (Multiply
MUL {<cond>}{S} Rd, Rm, Rs
•
Con S = 1 si modificano i bit N, Z, C (non prevedibile).
•
L’istruzione esegue il prodotto con o senza segno del contenuto in Rm con il contenuto
di Rs e pone il risultato da 32 bit in Rd.
Esempio
MULEQ R0, R1, R2 ;se Z=1 allora R0 <- R1*R2
MVN (Move Negative o Move Negated)
MVN {<cond>}{S} Rd, <shifter_operand>
•
Con S = 1 si modificano N, Z, C (non prevedibile).
•
L’istruzione esegue il complemento a 1 dello <shifter_operand> e lo pone in Rd.
Se i bit di condizione sono modificati, i nuovi valori dipendono da Rd e dal carry
dello <shifter_operand>.
Esempio
MVN R3, 0
;R3 <- NOT(0)=0xffffffff=−1
ORR (Bitwise logical OR)
ORR{<cond>}{S} Rd, Rn, <shifter_operand>
•
Con S = 1 si modificano N, Z, C.
•
L’istruzione esegue una OR bit a bit tra il contenuto di Rn e il contenuto dello
<shifter_operand>; il risultato viene posto in Rd. Se lo <shifter_operand> viene usato
come maschera, si possono mettere a 1 tutti i bit di Rn.
Esempio
ORR R0, R0, 0x1
;pone a 1 il bit meno significativo di R0
RSB (Reverse Subtract)
RSB{<cond>}{S} Rd, Rn, <shifter_operand>
•
Con S = 1 si modificano N, Z, C, V#.
•
L’istruzione esegue la sottrazione tra Rn e lo <shifter_operand>, ponendo il
risultato in Rd.
Esempio
RSB Rd, Rx, #0
;Rd <- −Rx
RSB Rd, Rx, Rx LSL #3
;Rd <- Rx*7
RSC (Reverse Subtract with Carry)
RSC{<cond>}{S}Rd, Rn, <shifter_operand>
•
L’istruzione sottrae Rd da <shifter_operand>; al risultato viene sottratto il complemento
di C; il risultato finale in Rd.
Esempio
Il programma esegue il complemento a 2 di un dato a 64 bit: R0 bit meno significatici,
R1 bit più significativi.
RSBS R2, R0, #0
;R2 <- −R0 , C! prestito
RSC R3, R1, #0
;R3 <- −R1 <- !C
SBC (Subtract with Carry)
SBC{<cond>}{S}Rd, Rn, <shifter_operand>
•
Con S = 1 si modificano N, Z, C, V.
•
L’istruzione sottrae da Rn il contenuto di <shifter_operand>; al risultato viene sottratto
il complemento di C; il risultato finale è posto in Rd
Esempio
Il programma svolge la differenza tra 2 dati a 64 bit:
R0R1 − R2R3 = R4R5.
SUBS R4, R0, R2
;sottrazione bit meno significativi
SBC R5, R1, R3
;sottrazione bit più significativi
SMLAL (Signed Multiply Accumulate Long)
SMLAL {<cond>}{S} RdLo, RdHi, Rm, Rs
•
Con S = 1 si modificano N, Z, C (non prevedibile), V (non prevedibile).
•
L’istruzione esegue il prodotto di Rm con Rs e somma il risultato su 64 bit con segno
a RdLo (32 bit meno significativi) e RdHi (32 bit più significativi).
Esempio
SMLAL R0, R1, R2, R3, R4
;[R1 R0] + R3*R4 con segno
SMULL (Signed Multiply Long)
SMULL{<cond>}{S} RdLo, RdHi, Rm, Rs
•
Con S = 1 si modificano N, Z, C (non prevedibile), V (non prevedibile).
•
L’istruzione esegue il prodotto di Rm con Rd e somma il risultato su 64 bit con segno
in RdLo (32 bit meno significativi) e RdHi (32 bit più significativi).
Esempio
SMULL R0, R1, R2, R3, R4
;[R1 R0] ← R3*R4 ;con segno
SUB (Subtract)
SUB{<cond>}{S} Rd, Rn, <shifter_operand>
•
Con S = 1 si modificano N, Z, C, V.
•
L’istruzione esegue la sottrazione di <shifter_operand> da Rn e pone il risultato in Rd.
Esempio
SUB R0, R0, #8
;R0 <- R0-8
TEQ (Test Equivalence)
TEQ{<cond>} Rn, <shifter_operand>
•
Si modificano i bit N, Z, C.
•
L’istruzione esegue dei test sui bit di Rn perché fa la AND bit per bit tra il contenuto di
Rn e lo <shifter_operand> interpretata come maschera. I bit di condizione sono settati
in base al risultato. In tal modo si può valutare se i bit di Rn sono tutti nulli
TST (Test)
TST{<cond>} Rn, <shifter_operand>
•
Si modificano i bit N, Z, C.
•
L’istruzione esegue l’AND bit a bit tra il contenuto di Rn e lo <shifter_operand> e setta
i bit di condizione in base al risultato. Se lo <shifter_operand> è considerato come una
maschera si può valutare se i bit testati dalla maschera sono nulli.
Esempio
TST R0, #3
;i bit di condizione sono settati in base ai 2 bit meno significativi di R0
UMLAL (Unsigned Multiply Accumulate Long)
UMLAL{<cond>}{S} RdLo, RdHi, Rm, Rs
•
Con S = 1 si modificano N, Z, C (non prevedibile), V (non prevedibile).
•
L’istruzione esegue il prodotto tra Rm e Rs e somma il risultato senza segno su 64 bit a
RdLo (32 bit meno significativi) e a RdHi (32 bit più significativi) tenendo conto del
carry intermedio.
Esempio
UMLAL R0, R1, R3, R4
;[R1 R0] + R3*R4 senza segno
UMULL (Unsigned Multiply Long)
UMULL{<cond>}{S} RdLo, RdHi, Rm, Rs
•
Con S = 1 si modificano N, Z, C (non prevedibile), V (non prevedibile).
•
L’istruzione esegue il prodotto tra Rm e Rs e pone il risultato a 64 bit senza segno in
RdLo (32 bit meno significativi) e in RdHi (32 bit più significativi).
Esempio
UMULL R0, R1, R3, R4
;[R1 R0] <- R3*R4 senza segno
Istruzioni load e store
Le istruzioni load e store sono utilizzabili per:
•
trasferimento di dati multipli dalla memoria ai registri (load) e dai registri alla
memoria (store);
•
scambi tra contenuti di registri e memoria.
Le istruzioni load register servono per caricare nei registri dati con formato di una word
(32 bit), una halfword (16 bit) e un byte (8 bit) dalla memoria.
Il caricamento dei byte e delle halfword possono essere caricati in modo esteso a 32 bit
con 0 o con estensione di segno.
Le istruzioni store register servono per trasferire dai registri in memoria dati con formato
da una word (32 bit), una halfword (16 bit) o un byte (8 bit).
LDM (Load Multiple)
LDM{<cond>}<address> Rn(!), <registers> {^}
L’istruzione serve a caricare nei <registers> il contenuto delle locazioni di memoria indicate.
Esempio
LDMEQIA R1!, {R2-R4, R6}
;se Z=1 carica in R2, R3, R4 e R6 il contenuto delle
;locazioni di memoria W[R1], W[R1+4], ;W[R1+8],
;W[R1+12] e R1 <- R1+16
LDR (Load Register)
LDR{<cond>} Rd, <address>
L’istruzione carica in Rd il contenuto della locazione di memoria con indirizzo
indicato in <address>.
Esempio
LDRPL R0, [R1], -R2
;se N=0 si ha R0 <- W[R1] e R1 <- R1-R2
LDRB (Load Register Byte)
LDR{<cond>}B Rd, <address>
Il contenuto del byte di memoria, con indirizzo specificato da <address>, viene trasferito
in Rd.
Esempio
LDRMIB R0, [R1]
;se N=1 si ha R0 <- B[R1]
LDRH (Load Register Halfword)
LDR{<cond>}H Rd, <address>
Il contenuto dell’halfword di memoria, con indirizzo specificato da <address>, viene
trasferito in Rd. Il dato da 16 bit senza segno viene caricato in Rd e completato con
gli 0.
Esempio
LDRCSH R0, [R1,#20]
;se C=1 si ha R0 <- H[R1+20]
LDRSB (Load Register Signed Byte)
LDR{<cond>}SB Rd, <address>
L’istruzione preleva il contenuto di memoria all’indirizzo indicato in <address> e lo
carica in Rd su 32 bit con segno.
Esempio
LDRVCSB R0, [R1,#-10]
;se V=0 si ha R0 <- ext32(B[R1-10])
LDRSH (Load Register Sign Halfword)
LDR{<cond>}SH Rd, <address>
L’istruzione preleva l’halfword dalla memoria il cui indirizzo è specificato da
<address> e lo pone in Rd. Il dato a 16 bit è caricato in modo esteso a 32 bit + segno.
Esempio
LDREQSH R0, [R1, R2]!
;se Z=1 si ha R0 <- ext32(H[R1+R2])
;R1 <- R1+R2
STM (Store Multiple)
STM{<cond>}<address> Rn(!), <registers> {^}
L’istruzione trasferisce il contenuto dei registri specificati in <registers> in locazioni di
memoria indicate in <address>.
Esempio
STMNEDA R1, {R2-R4, R6}
;se Z=0, R2 R3 R4 R6 vengono copiati in W[R1] W[R1-4]
;W[R1-8] W[R1-12]
STR (Store Register)
STR{<cond>} Rd, <address>
Il dato presente in Rd viene trasferito nella word di memoria il cui indirizzo è
specificato da <address>.
Esempio
STR R0, [R1, R2, RRX]!
;W[R1+RotRightWithCarry (R2)] <-R0
;R1 <- R1+RotRightWithCarry (R2)
STRB (Store Register Byte)
STR{<cond>}B Rd, <address>
L’istruzione preleva il byte meno significativo di Rd e lo trasferisce nel byte di memoria
il cui indirizzo è specificato da <address>.
STRH (Store Register Halfword)
STR{<cond>}H Rd, <address>
L’istruzione preleva l’halfword meno significativo di Rd e lo trasferisce nel byte di
memoria il cui indirizzo è specificato da <address>.
Esempio
STRNEH R0, [R1], -R2
;se Z=0 si ha H[R1] <- R0H
;R1 <- R1-R2
Modi di indirizzamento dei 2 operandi.


Modi di indirizzamento
Operando 1
Operando 2
Costante
x
x
Registro
x
x
Offset addressing
x
Logical shift left
x
Logical shift right
x
Rotate right
x
Pre-index addressing
x
Post-index addressing
x
Modi di indirizzamento
I modi di indirizzamento sono le modalità con
cui vengono indicati gli operandi da manipolare.
Nella tabella a lato sono riassunte le modalità
relative ai due operandi.
Dalla tabella si nota che, a differenza dell’ope-
-rando 2, sull’operando 1 si possono effettuare
operazioni matematiche mediante shiftamento
nel Barrell Shifter.
L’operando quindi può essere modificato prima
di essere usato allo scopo di facilitare la compi-
-lazione di liste, tabelle e strutture di dati
complessi.
Esempio
Indirizzamento con valore immediato costante dell’operando 1:
MOV R0,#6784
;pone il dato (6784)10 nel registro R0
Esempio
Indirizzamento con registro dell’operando 1:
MOV R0, R1
;pone in R0 il contenuto di R1
Esempio
Indirizzamento Logical Shift Left con valore immediato costante dell’operando 1:
MOV R0, R1, LSL #4
;in R0 viene posto il valore di R1 shiftato di 4 bit vero la
;posizione più significativa, il contenuto di R1 non cambia
Esempio
Indirizzamento Logical Shift Left con registro dell’operando 1:
MOV R0, R1, LSL R2
;in R0 viene posto il contenuto di R1 shiftato verso sinistra di
;un valore che si trova nel registro R2. R0 è il solo registro che
cambia valore mentre R1 e R2 restano invariati.
Esempio
Indirizzamento Logical Shift Right con valore immediato costante dell’operando 1.
MOV R0, R1, LSR#4
;in R0 viene posto il valore di R1 shiftato a destra di 4 bit, con
;questo tipo di istruzione si può eseguire una divisione senza
;segno per 2n; il valore di R1 non cambia
Esempio
Indirizzamento Logical Shift Right with register dell’operando 1.
MOV R0, R1, LSR R2
;in R0 viene posto il contenuto di R1 shiftato di un valore
;indicato nel registro R2
Esempio
Indirizzamento Arithmetic Shift Right con valore immediato costante dell’operando 1.
MOV R0, R1, ASR #4
;R0 contiene il dato di R1 shiftato a destra di 4 posizioni e
;mantiene il bit più significativo con questa istruzione si può
;eseguire la divisione per 2n con segno poiché R0 conserva
;il bit più significativo
Esempio
Indirizzamento Arithmetic Shift Right con registro dell’operando 1.
MOV R0, R1, ASR R2
;R0 contiene il dato di R1 shiftato a destra di un valore indicato
;da R2 e mantiene il bit più significativo con questa istruzione
;si può eseguire la divisione per 2n con segno poiché R0
;conserva il bit più significativo
Esempio
Indirizzamento Rotate Right con valore immediato costante dell’operando 1.
MOV R0, R1, ROR#4
;il contenuto di R1 viene ruotato verso destra di 4 posizioni
;passando attraverso il flag C e da questo nella posizione più
;significativa di R1; il dato non viene perso e così ruotato è
;memorizzato in R0, il contenuto di R1 rimane inalterato
Esempio
Indirizzamento Rotate Right con registro dell’operando 1.
MOV R0, R1, ROR R2
;il contenuto di R1 ruota di un numero di bit indicato in R2
Esempio
Indirizzamento Rotate Right Extended dell’operando 1.
MOV R0, R1, RRX
;in R0 viene posto il contenuto di R1 ruotato attraverso il Carry, il C,
;ruotando ;va nel bit più significativo di R1 e il bit meno significativo
;di R1 va nel C
Esempio
Indirizzamento Offset Addressing dell’operando 2.
LDR R0, [R1]
;in R0 viene caricata una word a 32 bit il cui indirizzo di memoria è
;contenuto in R1, in questa istruzione l’offset è nullo, il contenuto di
;R1 rimane invariato
Esempio
Indirizzamento Offset Addressing dell’operando 2.
LDR R0, [R1 #2]
;R0 viene caricato con il dato della memoria il cui indirizzo si ottiene
;sommando 2 all’indirizzo contenuto in R1, il contenuto di R1 rimane
;invariato
Esempio
Indirizzamento Offset Addressing dell’operando 2.
LDR R0, [R1, R2]
;R0 viene caricato con il dato della memoria il cui indirizzo si calcola
;sommando l’indirizzo di R1 con l’indirizzo di R2, i contenuti di R1 e
;R2 rimangono invariati
Esempio
Indirizzamento Offset Addressing dell’operando 2.
LDR R0, [R1, R2, LSL #2]
;R0 verrà caricato con il dato della memoria il cui indirizzo
;si ottiene sommando l’indirizzo di R1 con l’indirizzo
;ruotato di 2 verso sinistra di R2, i contenuti di R1 e R2
;rimangono inalterati
Esempio
Indirizzamento Pre-Index Addressing dell’operando 2.
LDR R0, [R1, #2]!
;R0 sarà caricato con la word il cui indirizzo di memoria è
;ottenuto sommando la costante 2 all’indirizzo di memoria
;contenuto in R1, l’istruzione è di tipo write-back, ovvero in R1
;vi è il nuovo indirizzo calcolato con l’offset
Esempio
LDR R0, [R1, R2]
;R0 verrà caricato con il valore della memoria il cui indirizzo si
;ottiene sommando l’indirizzo di R1 con quello di R2, R2 resta
;invariato mentre R1 contiene il nuovo indirizzo
Esempio
Indirizzamento Pre-index Addressing dell’operando 2.
LDR R0, [R1, R2, LSL #2]!
;R0 sarà caricato con il dato a 32 bit della memoria il cui
;indirizzo si ottiene sommando il contenuto di R1 con il
;contenuto di R2 shiftato verso sinistra di 2 posizioni,
;l’istruzione è di tipo write back ovvero il nuovo indirizzo è
;memorizzato in R1 mentre R2 rimane invariato
Esempio
Indirizzamento Post-Index Addressing dell’operando 2.
LDR R0, [R1], #2
;R0 sarà caricato con la word di memoria il cui indirizzo è
;contenuto in R1, successivamente in R1 verrà caricato il
;nuovo indirizzo ottenuto sommando quello corrente con la
;costante 2
Esempio
Indirizzamento Post-Index-Addressing dell’operando 2.
LDR R0, [R1], R2
;R0 sarà caricato con la word di memoria il cui indirizzo si trova nel
;registro base R1, successivamente in R1 verrà memorizzato il
;nuovo indirizzo ottenuto sommando a R1 la costante contenuta in
;R2, R2 rimane invariato
Esempio
Indirizzamento Post-Index Addressing dell’operando 2.
LDR R0, [R1], R2, LSL #2
;R0 sarà caricato con la word di memoria il cui indirizzo si
;trova nel registro base R1, in R1 verrà memorizzato il
;nuovo indirizzo che si ottiene sommando R2 shiftato del
;valore costante 2
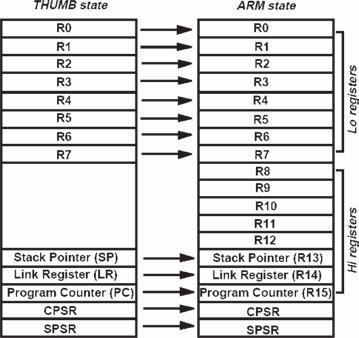
Thumb mode
Una delle caratteristiche avanzate dei moderni
micro sono le ottimizzazioni per limitare il
tempo di compilazione o l’uso della memoria o
per raggiungere un compromesso tra velocità
e spazio occupato dall’eseguibile generato
dalla compilazione.
Negli ARM è stata implementata l’ottimiz-
-zazione per diminuire le dimensioni del codice.
Tale ottimizzazione prende il nome di Thumb
mode e consente la compressione del codice.
La modalità Thumb si serve di un set di
istruzioni alternativo a 16 bit che compie le
stesse operazioni di quello standard ARM che
è a 32 bit.
La modalità Thumb utilizza solo i primi 8
general purpose registers invece che 15
(vedi figura a lato), solo alcune istruzioni,
quali ad esempio MOV e CMP, utilizzano tutti
i registri.
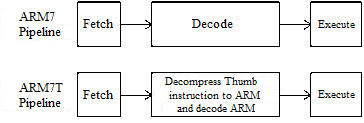
Nella successiva figura a lato, sono illustrate
le fasi di elaborazione delle istruzioni nelle
due modalità ARM standard e Thumb.
Con la modalità Thumb si ottiene un risparmio
di un 35% circa di memoria poiché è sufficiente
meno memoria per contenere lo stesso numero di
istruzioni, o in alternativa si può affermare che nello stesso spazio di memoria entrano più
istruzioni.
Si ottiene inoltre anche una semplificazione del codice.
La modalità Thumb è impostabile in qualsiasi momento e posizione all’interno del
programma.
La velocità di esecuzione risulta però ridotta perché il codice Thumb deve essere
decompresso nel codice ARM standard, infatti il micro non ha istruzioni separate.
Il Thumb mode non gestisce le eccezioni; quando si verificano è sempre necessaria la
conversione in ARM standard.
La limitazione del modo Thumb deriva dalla necessità di convertire ogni istruzione
nell’equivalente ARM, anche se la perdita delle prestazioni non è molto significativa rispetto
al risparmio di spazio.
È possibile tuttavia utilizzare la programmazione di tipo interworking, ovvero una program-
-mazione che si serve sia del codice Thumb sia del codice ARM standard.
Il vantaggio che ne deriva è che si può decidere a livello di subroutine se dare maggiore
peso al risparmio di memoria oppure alle prestazioni.
Ad esempio il codice è molto restrittivo in termini prestazionali quando vi sono delle
eccezioni, quindi in questo caso si utilizza il codice ARM standard, rinunciando ovviamente
al risparmio di memoria.
Per tutte le altre operazioni si può utilizzare il Thumb mode.
Mappatura dei registri dello stato Thumb
sullo stato ARM (ARM Powered).
Fasi di elaborazione delle istruzioni
in ARM standard e Thumb mode
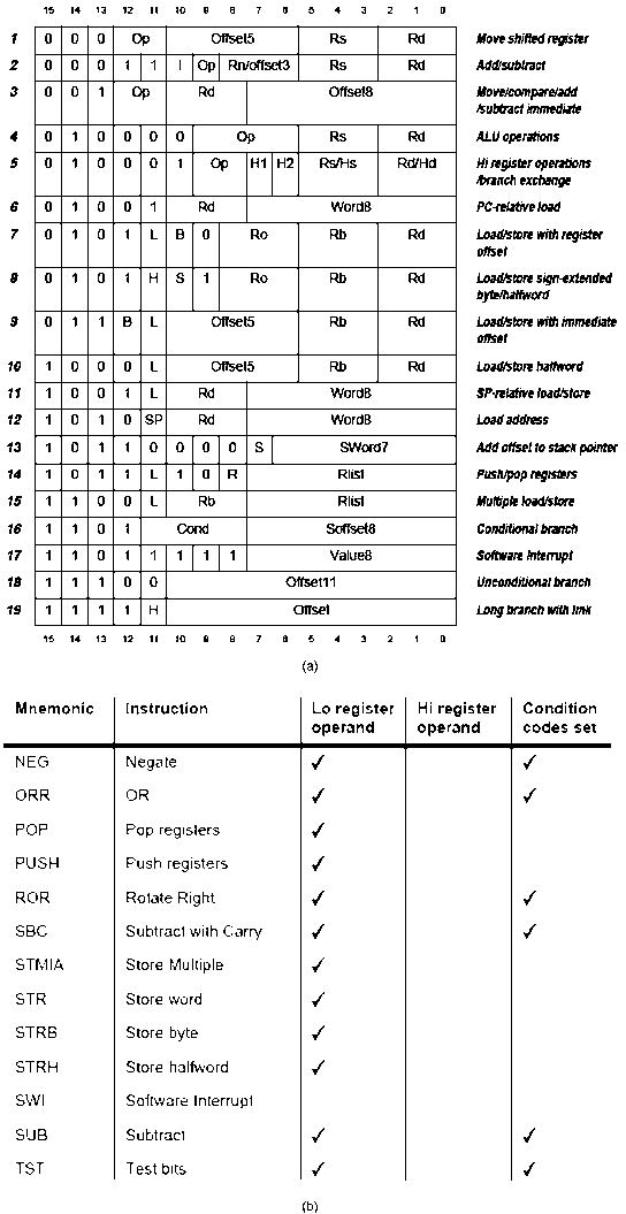
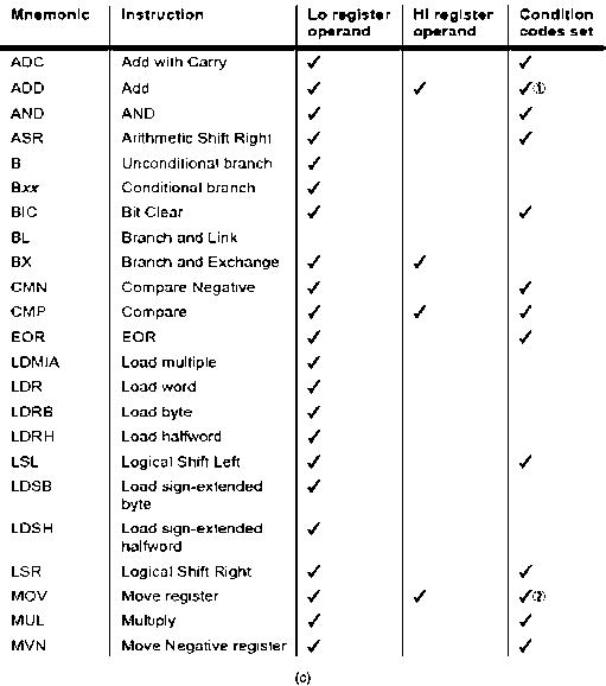
Set di istruzioni in ARM e Thumb mode
Nelle due sottostanti figure sono riportati il formato e il set delle istruzioni nello stato ARM.
Nelle seguenti figure (a), (b) e ( c), sono riportati il formato e il set delle istruzioni nel
modo Thumb
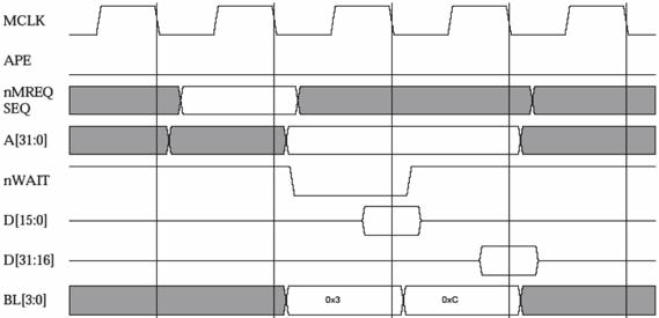
Nella seguente figura è illustrato il diagramma temporale relativo all’operazione di accesso
alla memoria.
Nell’operazione è stato introdotto un tempo di attesa.
Formato (a) e set (b, c) delle istruzioni nel modo Thumb
del microcontrollore ARM (ARM Powered).
Esempio di lettura in memoria con uno stato di attesa (ARM Powered)
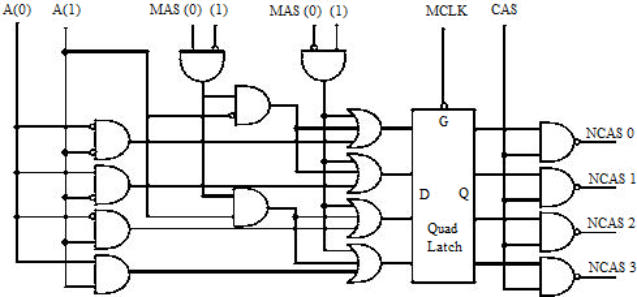
Circuito di decodifica per l’accesso alla memoria esterna


Lorem Ipsum Dolor
Cupidatat excepteur ea dolore sed in adipisicing id? Nulla lorem deserunt aliquip officia reprehenderit fugiat, dolor excepteur in et officia ex sunt ut, nulla consequat. Laboris, lorem excepteur qui labore magna enim ipsum adipisicing ut. Sint in veniam minim dolore consectetur enim deserunt mollit deserunt ullamco. Mollit aliqua enim pariatur excepteur. Labore nulla sunt, in, excepteur reprehenderit lorem fugiat. Ipsum velit sunt! Non veniam ullamco amet officia ut, ex mollit excepteur exercitation fugiat eu ut esse cupidatat in velit. Non eu ullamco in pariatur nisi voluptate mollit quis sed voluptate ea amet proident dolore elit. Occaecat nostrud dolore sunt, ullamco eu ad minim excepteur minim fugiat. Nostrud culpa eiusmod dolor tempor et qui mollit deserunt irure ex tempor ut dolore. Dolore, nostrud duis ad. In nulla dolore incididunt, sit, labore culpa officia consectetur mollit cupidatat exercitation eu. Aute incididunt ullamco nisi ut lorem mollit dolore, enim reprehenderit est laborum ut et elit culpa nulla. Excepteur fugiat, laboris est dolore elit. In velit lorem id, et, voluptate incididunt ut ad in sunt fugiat, esse lorem. Nisi dolore ea officia amet cillum officia incididunt magna nisi minim do fugiat ut nostrud dolore Qui in est in adipisicing ea fugiat aliqua. Reprehenderit excepteur laboris pariatur officia sit amet culpa aliquip quis elit eiusmod minim. Sint ut ut, proident in mollit do qui eu. Pariatur et cupidatat esse in incididunt magna amet sint sit ad, sunt cillum nulla sit, officia qui. Tempor, velit est cillum sit elit sed sint, sunt veniam.





© Irure ut pariatur ad ea in ut in et. In incididunt sed tempor

